

Another year has passed with more crises in online Trust and Safety than solutions. Hate speech, child abuse, and public health misinformation prevail across platforms, and the new virtual reality Meta has already proven inescapable from the persistent reality of sexual harassment [1]. A lot of attention has been focused on how technology companies, lawmakers, and academics can solve Trust and Safety problems. In this article, however, I will bypass the big players and will instead show you how ordinary users deal with toxic content. Their experience teaches us that, contrary to popular perception, content removal is not always binary or straightforward. It is rather often a multi-step process of exchanges and negotiation among the participants.
The case I will be examining is toxic speech in the online conversations among Wikipedia editors [2]. Wikipedia relies on volunteers for both content creation and moderation. With civility being one of its five pillars, Wikipedia editors are expected to behave politely and thwart impolite behavior in others. They are, for instance, vigilant for vandals who wipe out legitimate edits on Wikipedia entries [3]. They also monitor user discussion during the editing process [4]. In interviews, Wikipedia users had reported deploying watchlists, noticeboards, abuse logs, and more to search widely for harmful speech [5]. Severely toxic comments were deleted at a rate of 82 percent within a day [6]. How do Wikipedia editors do it? Drawing from the publicly available Wikipedia user activity logs [7], I will reconstruct how removal of toxic comments unfolds on Wikipedia in a step-by-step fashion. In case you are wondering, no, it is not as simple as a yes-no question.
I began by drawing a balanced random sample of nearly 400,000 toxic and nontoxic comments from Wikipedia user conversations [8]. I determined whether a comment is toxic or not using the Perspective API [9]. A toxic comment is defined as a “rude, disrespectful, or unreasonable comment that is likely to make people leave a discussion.” Next, for each seed comment, I traced all the user actions targeted at it and built a sequence from the user actions. The sequence may be made up of six types of actions: archive, modify, remove, reply, restore, and stay (which means no action, leaving the comment on the page). Below is an example of a sequence of length three, remove-restore-remove (Figure 1). It demonstrates how a toxic comment was removed, restored by the original author, and ultimately removed by a third user.
Figure 1: An Example of User Response Sequence, Remove-Restore-Remove [10]

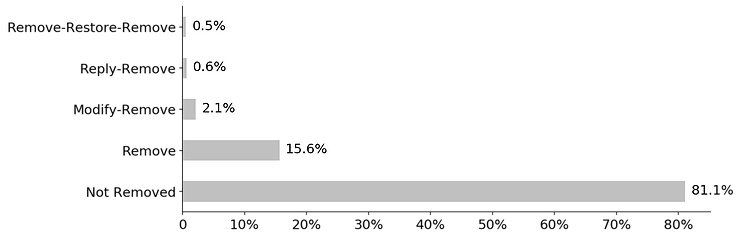
Sequences built in this way vary considerably by length and composition, which reflect the heterogeneity in responses to comments. To make sense of the data, I applied a clustering technique to group similar sequences together and identify the common patterns in the sequences [11]. My overall finding is that there are multiple paths leading up to content removal (Figure 2). We tend to focus on the straightforward single act of removal. Indeed, single-step removal is the most common (15.6 percent of all comments, or 83 percent of removed comments). Nevertheless, a significant number of content removal (3.2 percent of all comments, or 17 percent of removed comments) took more than one exchange. Specifically, in 2.1 percent of cases, removal was preceded by a modification action (modify-remove), and 0.6 percent preceded by a reply (reply-remove). The most complex pattern (0.5 percent), which I termed disputed sanction, involves a removed comment being restored, only to be removed again (remove-restore-remove; see example in Figure 1). Repeated undos are generally contentious and harmful to collaboration [12].
Figure 2: Typology of Content Removal
Do toxic and nontoxic comments fare differently? Unsurprisingly, toxic comments are more likely to be removed in every single way than nontoxic comments are. Nonetheless, many toxic comments (65.5 percent) were not censored at all (Figure 3). The gap warrants further investigation as it may reflect the limits of peer content moderation or misclassification of toxic comments.
Figure 3: Distribution of Comment Outcomes by Toxicity
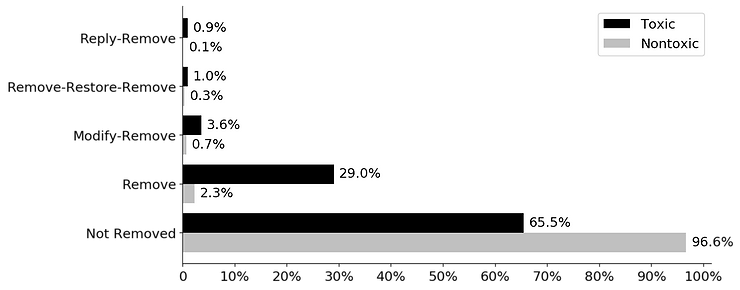
(Percentage is calculated separately within toxic or nontoxic comments)
Watching closely how Wikipedia users dealt with toxic comments highlights two critical factors in Trust and Safety, context and heterogeneity. Content moderation, for users, is not always a black-and-white decision, but rather a meaningful social process. Repeated removal and restoration, for example, imply disagreement and conflict. Replying to a toxic comment before removal may suggest an attempt at reconciliation before forcible action (Figure 2). Bringing the conversational context into platform moderation has shown promise of proactively predicting conversational failures [13] and improving classifier performance [14]. At Trust Lab, the user-sentiment-based content classifier product that we are currently developing is another effort to integrate context into the moderation process. We complement a priori content policy with collective user sentiment to make content moderation recommendations.
Another theme in content moderation is its nonbinary multiplex nature. Wikipedia users choose from a variety of strategies when responding to toxic content, rather than a binary choice of to remove or not to remove. It further appears questionable whether deletion is the only criterion for content moderation success. If the response pattern reply-remove is a clear instance of successful moderation, how about reply-modify? That is, is a toxic comment resolved through modification also a success? Is it even preferable to removal? An adequate toolkit of content moderation should be able to account for certain variations in user dynamics.
To sum up, to remove or not to remove, that is not the question. The question is how to remove, as shown in the relational and cultural complexity surrounding Wikipedia users' experience with content moderation.
-------------------------------
Sources:
[1] The metaverse has a groping problem already (https://www.technologyreview.com/2021/12/16/1042516/the-metaverse-has-a-groping-problem/). Last accessed on January 19, 2022 (same for the following links).
[2] I refer to users who edit or moderate Wikipedia articles as editors, as opposed to readers who only consume articles.
[3] Testing Coleman’s Social-Norm Enforcement Mechanism: Evidence from Wikipedia (https://www.journals.uchicago.edu/doi/10.1086/689816)
[4] Each Wikipedia article is accompanied by a talk page, where volunteers discuss and coordinate edits (https://en.wikipedia.org/wiki/Help:Talk_pages). A talk page is organized into discussion threads, each of which contains a heading and (nested) comments. The data in this analysis come from conversations on the English Wikipedia article talk pages.
[5] Content and Conduct: How English Wikipedia Moderates Harmful Speech (https://dash.harvard.edu/handle/1/41872342)
[6] WikiConv: A Corpus of the Complete Conversational History of a Large Online Collaborative Community (https://arxiv.org/abs/1810.13181)
[7] WikiConv: A Corpus of the Complete Conversational History of a Large Online Collaborative Community (https://arxiv.org/abs/1810.13181)
[8] Only new original comments that start a new thread or reply to an existing thread qualify for my sample. Modified or restored comments do not qualify.
[9] The definition and measurement of toxicity both come from the Perspective API (https://www.perspectiveapi.com/). The API predicts the probability that an input is toxic (a value between 0 and 1). I consider comments with scores equal to or above 0.667 as toxic. My findings remained robust when I applied alternative thresholds of toxicity.
[10] The sequence does not record user attributes or time elapsed between actions.
[11] To provide more technical details, I first derived a pairwise distance matrix between sequences using optimal matching, which determines the distance between two sequences by the cost of transforming one sequence into another via insertion, deletion, or substitution. Next, I ran the k-medoids algorithm with the distance matrix to identify clusters.
[12] In response to repeated undos, Wikipedia has instituted a three-revert rule, meaning no more than three reverts on a single page in a 24-hour period from the same user (https://en.wikipedia.org/wiki/Wikipedia:Edit_warring#The_three-revert_rule).
[13] Conversations Gone Awry: Detecting Warning Signs of Conversational Failure (https://arxiv.org/abs/1805.05345)
[14] How Pinterest powers a healthy comment ecosystem with machine learning (https://medium.com/pinterest-engineering/how-pinterest-powers-a-healthy-comment-ecosystem-with-machine-learning-9e5c3414c8ad)
Related Posts & Articles


