

Trust in AI through Monitoring, Evaluation and Autodidact Learning
Our Differentiation: Certified AI Agent Quality

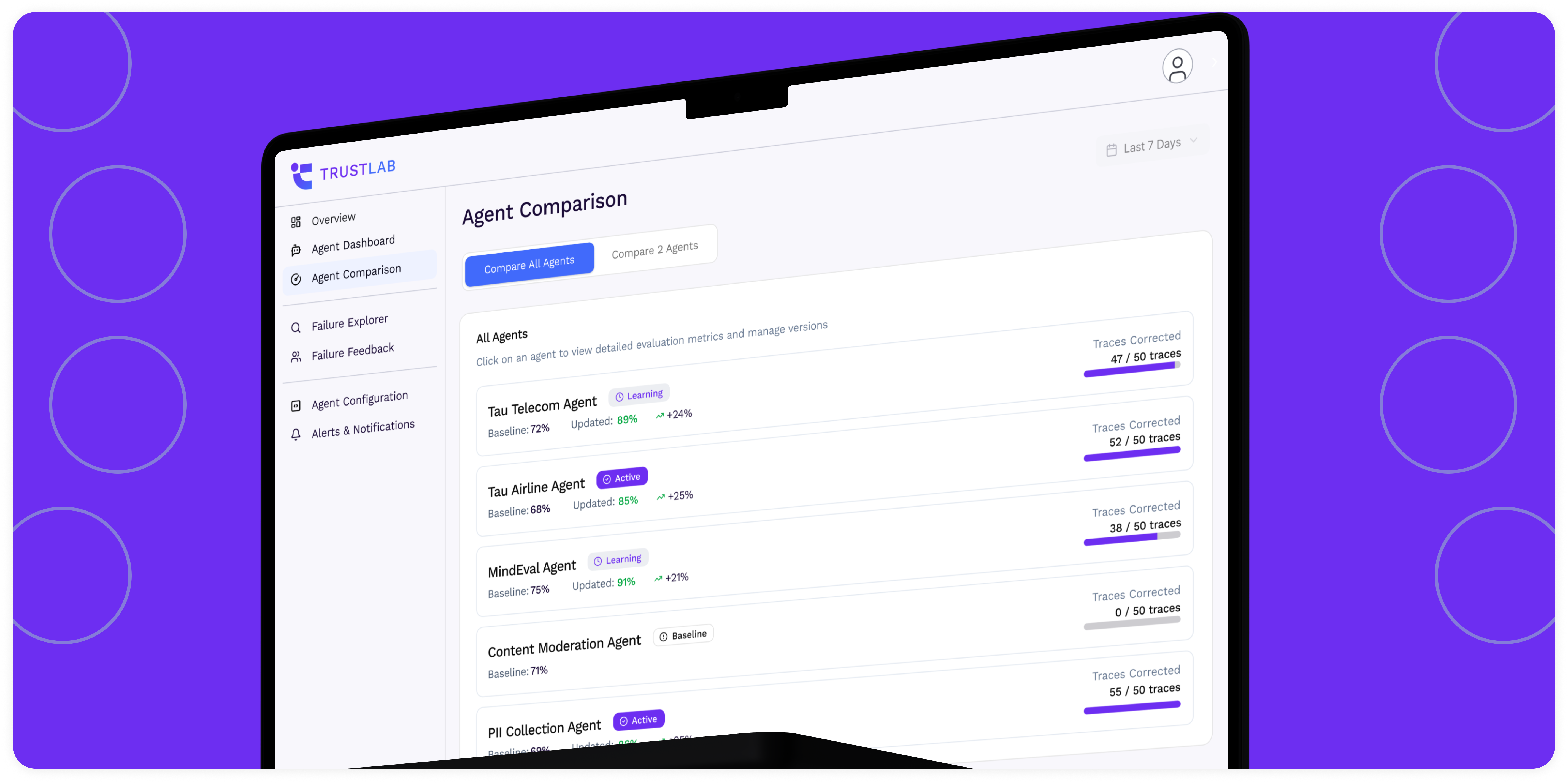
Know what your AI agent does with certainty
Our roots in nuanced, subjective, and high-stakes judgments (beyond “routine” labeling) give you safety-grade accuracy with less human review because we target the right samples.

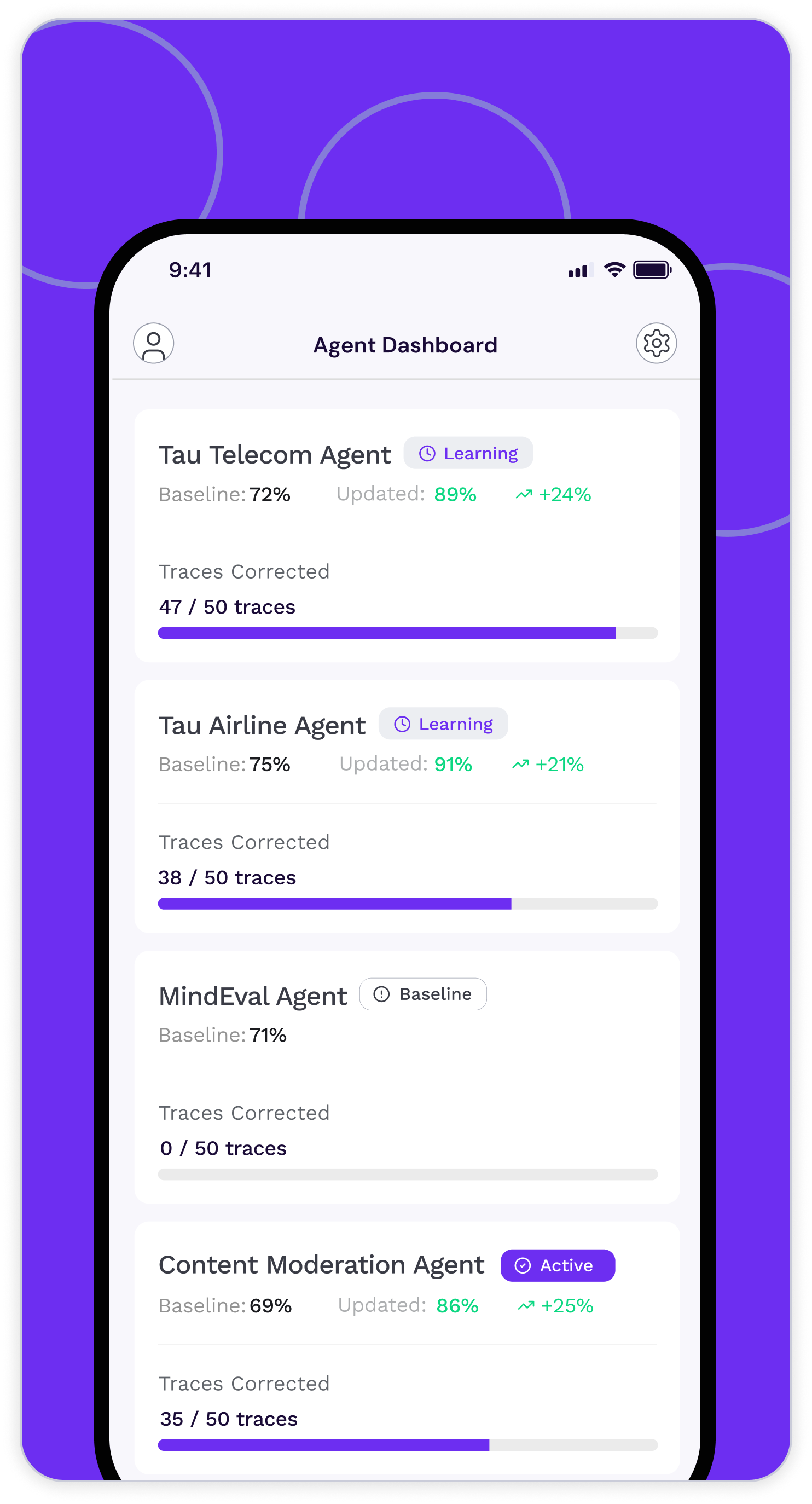
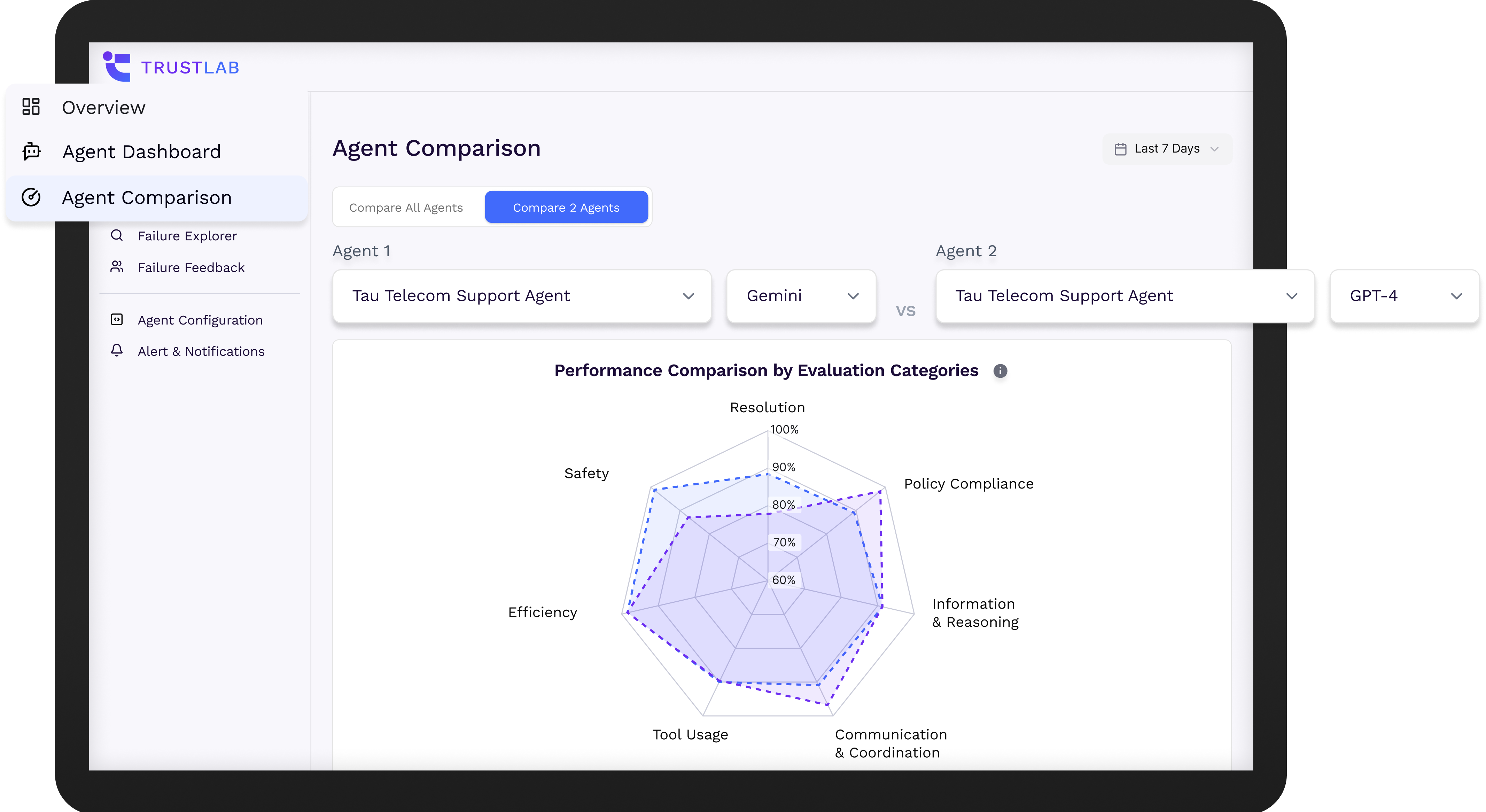
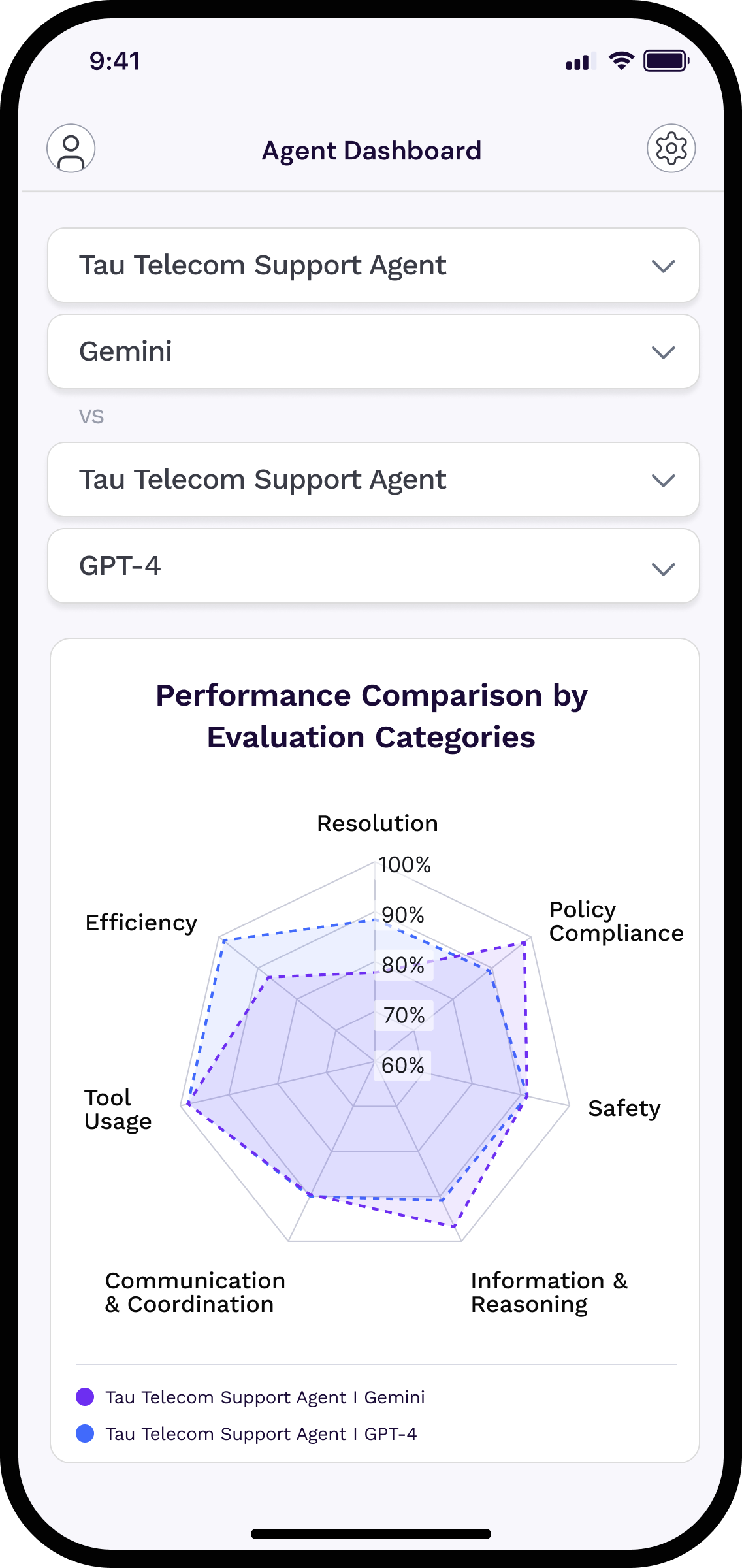
Visualize AI agent health in dashboards
Gain instant clarity into how your AI agents perform, behave, and improve with live metrics that turn invisible risks into actionable insights.

Auditor-ready from day one
Versioned suites, evidence bundles, and clear error case analysis without months of bespoke work.

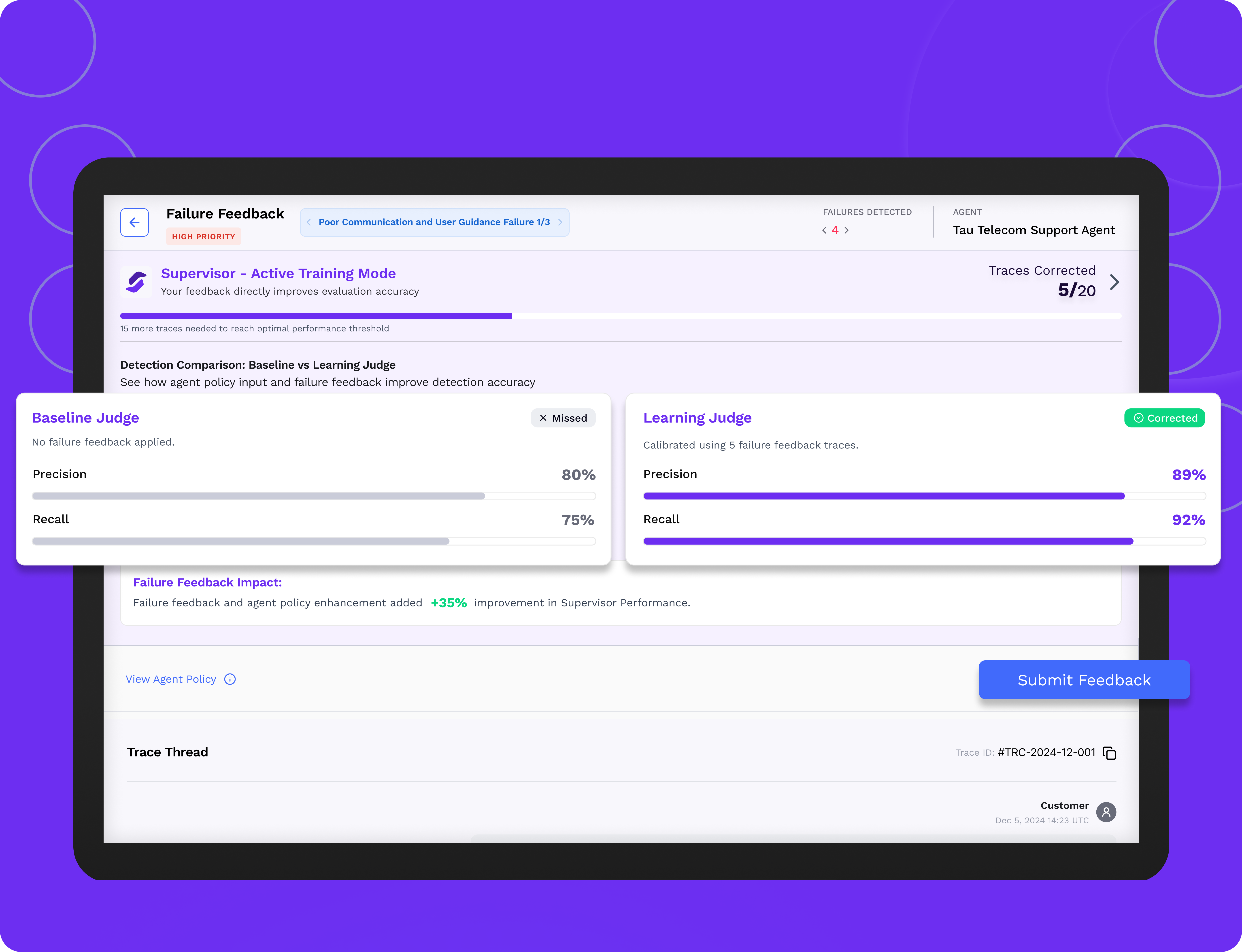
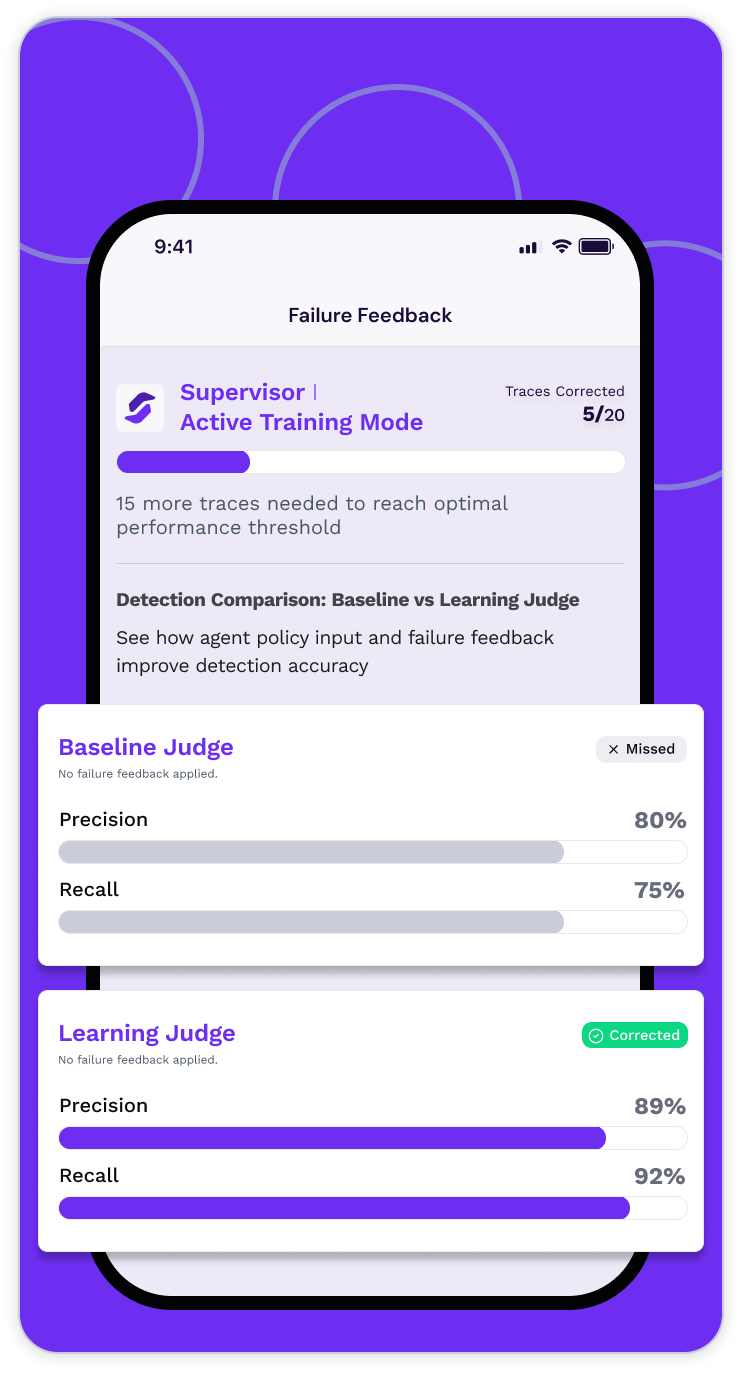
Automate AI agent learning processes
Continuously optimize your AI agents with closed-loop feedback and reinforcement learning that scales quality without manual retraining.
Why SuperviseAI?
Trusted Quality Benchmarks
Our LLM-as-a-Judge evaluations identify agent failures in nuanced, reference-free contexts (not just pass/fail code checks).
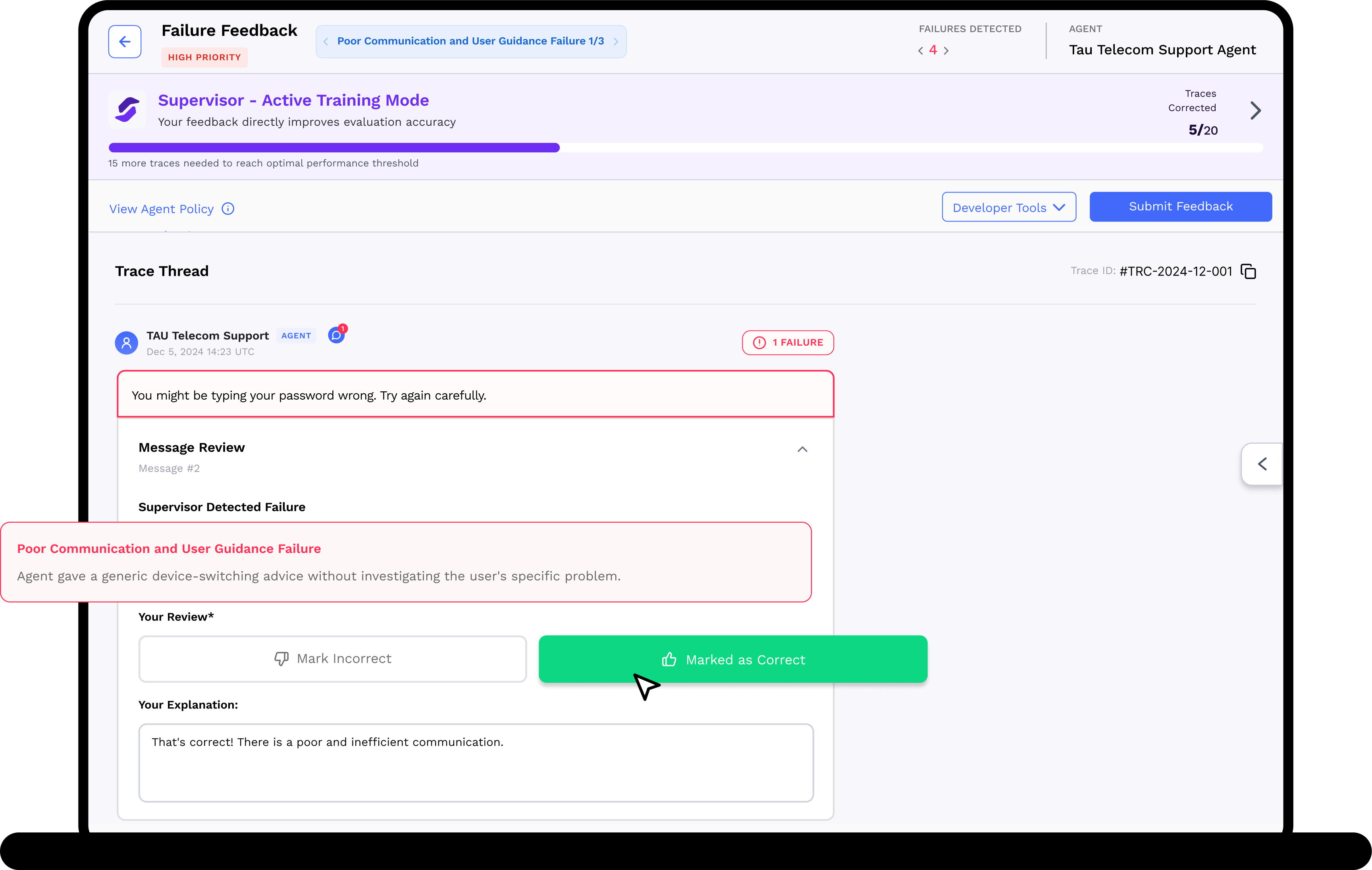
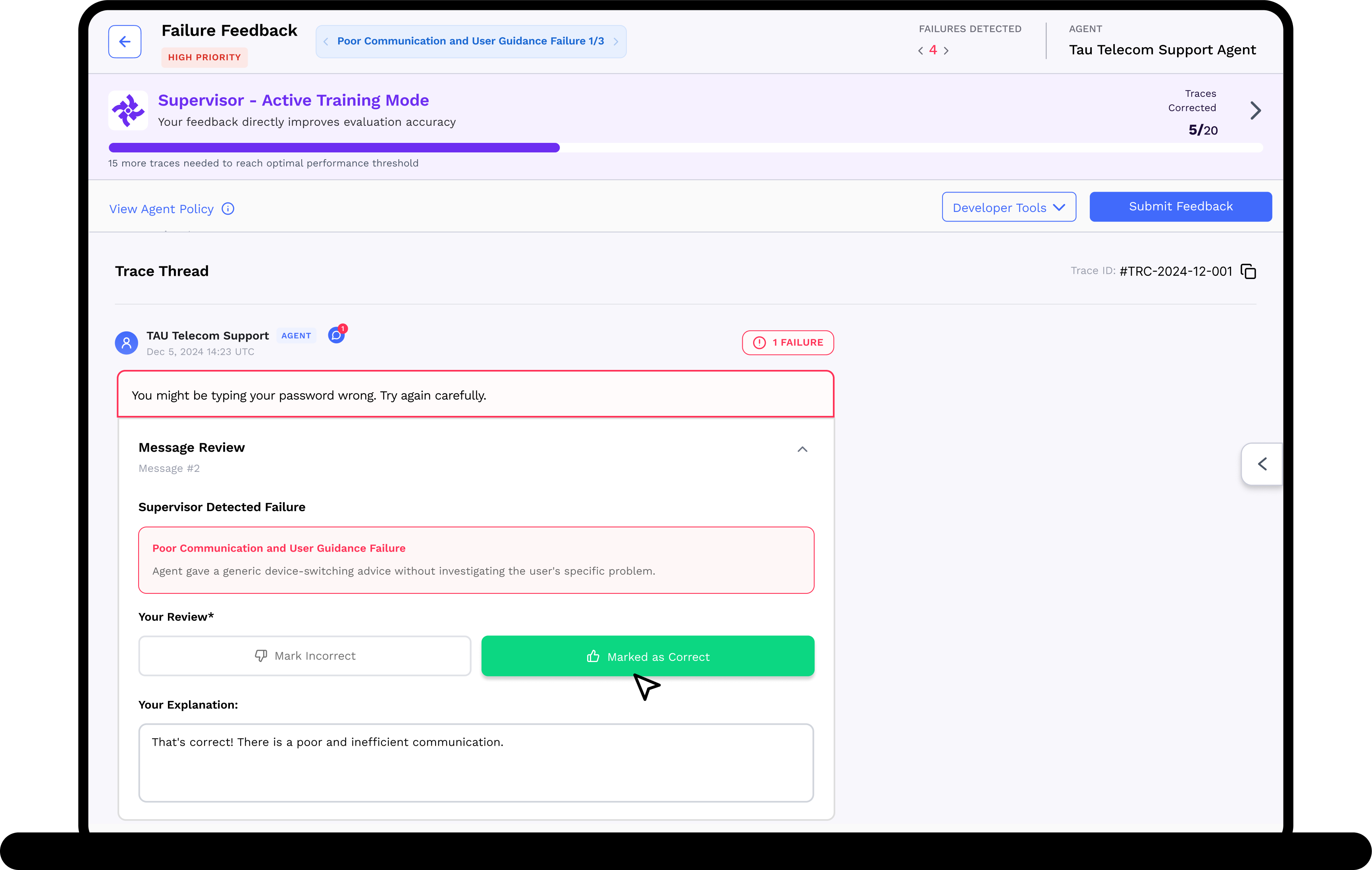
Human Oversight
We use human feedback where it matters. Failure mode prioritization, failure sampling, and accessible review tooling optimizes human misalignment feedback.
Real-Time, Actionable Reports
We provide full transparency with real-time dashboards, error case analysis, and trend analysis to clarify agent performance over time.
Ongoing, Automated Improvement
From monitoring to continuous quality improvement, we close the loop through a reinforcement feedback learning cycle powered by error case analysis and human assessment context.
Creating Trust with Quality Measurement
SuperviseAI provides incident rates (safety, leakage, hallucinations), grounded-answer scores, time-to-adjudication, and clear error cases that measure your AI agent quality.
With SuperviseAI, you gain clear visibility into every action your AI takes so you can trust its performance, correct mistakes instantly, and sleep well knowing your AI agents are always under watch.
Tailored Evaluation Out-of-the-box
SuperviseAI creates custom evaluations automatically for your agents, based on agent behavior policy context. Specific failure modes map to evaluation categories such as safety / toxicity checks, PII/PHI leakage and redaction verification, prompt-injection and jailbreak resistance, hallucination and grounding assessments, action guardrails for allow/deny/approval, brand, sentiment, and suitability for UGC or ads, as well as bias, harassment, denial, and frustration detection.

What SuperviseAI Does
1. Always-On Quality & Risk Monitoring
Continuous, policy-driven evaluations across multi-turn, multi-tool and multimodal AI agent flows. Configurable alerts notify you of performance drift so you can minimize regression impact.
2. LLM-as-a-Judge, Reconciled with Humans
Policy-driven classifiers judge identify failure modes and related quality measures that are most important to your agent performance, like completeness, tone, bias, and safety / no-harm. All evaluation decisions include human-readable, step-by-step rationales for transparency.
3. Human Expert Adjudication
SuperviseAI routes high priority agent failures to expert reviewers (your team members, outsourced to TrustLab or to a 3rd party) for calibration, then automatically applies disagreements to improve evaluation accuracy and update error case analysis.
4. Reinforcement Learning and Reporting
Updated failure modes, scorecards and datasets are self-serve accessible and exportable so you know how your AI agent’s quality is measuring up, your team has the insights they need to improve quality, and your compliance/oversight reports are always current.
Where SuperviseAI Shines
Financial Services

Employee copilot and customer-facing chatbot supervision with audit-ready artifacts.
Healthcare

Monitoring and evaluating AI output for personalized treatment plans and care coordination.
Public Sector & Regulated Industries

Continuous, policy-mapped evaluations with HITL oversight.
UGC Platforms & Advertisers
Policy violation decisions with appeals to reduce over-blocking.
Agentic Startups & Enterprise Teams

Quality monitoring (accuracy, consistency, safety), drift alerts, and improvement loops as you scale agents.
How to Use SuperviseAI
SuperviseAI empowers teams to confidently deploy and manage AI agents by providing continuous oversight, performance evaluation, and real-time learning. It helps you ensure that your AI systems act responsibly, deliver consistent results, and comply with safety and privacy standards.
Test & Integrate SuperviseAI in Minutes
1. Connect your agents via API/MCP
2. Select quality evaluation suites
3. Observe LLM judge disagreements
4. Adjudicate with expert reviewers
5. Leverage judge+human feedback
6. See proof of quality improvement

Trust through Evidence: Metrics that Matter
Quality & Safety
• Efficiency
• Hallucination
• Policy Compliance
Reliability & Performance
• Jailbreak Resistance
• Resolution
• Tool Usage
Human Review Quality
• Reviewer Consistency
• Disagreement Rates
• Time-to-adjudication
Monitoring & Compliance
• Drift
• Regression alerts
• Performance Trends

Plan Options
Pilot

2 Evaluation Suites
1 Environment
25k Evals/Mo
Core Reports
Check Our Performance based on a Free Pilot
Pro
5 Evaluation Suites
3 Environments
100k Evals/Mo
Human Feedback Tooling
Dashboards and Alerts
Enterprise
Custom Evaluation Suites
Unlimited Environments
Unlimited Evals/Mo
On-Prem or VPC Deployment
Forward Deployed Eng Support
Frequently Asked Questions
Ready to de-risk your AI
agents and prove quality?


