

AI agents are rapidly evolving from mere "assistants" into autonomous decision-makers. They approve refunds, route complex support tickets, trigger automated workflows, and even draft legal clauses. These are actions that directly impact revenue, safety, compliance, and customer trust.
Unlike traditional software, agent behavior is non-deterministic. It shifts with model updates, prompt tweaks, and evolving real-world context. This creates an uncomfortable reality for AI teams: Most evaluation solutions produce scores, but they don't convincingly prove the agent is doing the correct thing.
To move from "vibe checks" to enterprise-grade reliability, we need to introduce the missing ingredient: adjudication.
The Crisis of Truth in AI Evaluation
For decades, software quality was a matter of determinism. If something broke, you traced it to a specific line of code. With agents, failures are subtle: a tool call made at the slightly wrong time, a hallucinated "fact" inserted into a workflow, or a policy boundary crossed only under specific pressure.
Currently, teams tend to fall into two common pitfalls:
1. The Scalability Paradox (LLM-as-a-Judge)
Deploying LLMs to evaluate other LLMs offers incredible scale. However, research consistently shows these judges carry systematic biases. Whether it’s position bias (preferring the first answer), verbosity bias (rewarding length over quality), or a tendency to favor LLM-generated text, these automated judges often provide crisp dashboards that are quietly, fundamentally wrong.
2. The Human Bottleneck
Human review provides the nuance needed for high-stakes decisions, but it fails to scale. Humans disagree, especially on edge cases and subjective policy. Without a way to resolve these disagreements, ‘human review’ often becomes a collection of inconsistent opinions rather than a source of ground truth.
Adjudication: The Conflict Resolution Layer
Adjudication is not simply "more review." It is a structured human + AI partnership designed to resolve disagreement and convert messy signals into reliable decisions. Instead of repeating the same review process, adjudication introduces a deliberate step where conflicting inputs are examined together. AI surfaces patterns, prior decisions, and risk signals at scale; human adjudicators apply judgment, policy interpretation, and real-world context. Together, they reconcile differences and arrive at a final, accountable outcome.
Think of it as the Supreme Court for your AI's behavior. For many workflows, this happens post-hoc to ensure the system is learning correctly. However, for high-stakes actions, adjudication can also act as the final sign-off. For example, while an AI agent can collect data and refine a mortgage application with a customer, the high-impact final call requires an adjudicator to provide the ultimate sign-off. Whether the adjudicator steps in because two models disagree or because the risk threshold demands it, they provide the final, defensible word.
The Three Pillars of Adjudicated Truth
To move beyond simple scoring, an adjudication framework relies on three pillars:
1. Triaged Oversight
Adjudication is most scalable when you don’t ask humans to re-examine every single decision, including high-confidence ones. Instead, the system should triage cases based on risk, uncertainty, or evaluator conflict. This allows the process to adapt to the stakes: high-impact actions can be held for real-time adjudication before they go live, while high-volume tasks are routed to an offline adjudication process. This offline layer acts as a high-fidelity evaluation tool, resolving subtle disagreements to build a ground truth audit trail and a library of defensible evidence. By triaging this way, human expertise is never wasted on the mundane, but is always present where the cost of failure is highest or the need for systemic proof is greatest.
2. Defensible Rationales
A number on a dashboard (e.g., “85% accuracy”) is not an audit trail. Metrics show outcomes, but they fail to capture the underlying reasoning. When a decision is questioned, whether by a customer or a regulator, a score alone cannot explain why an action was correct.
Adjudication shifts the focus from the outcome to the rationale. Every adjudicated decision records exactly why a specific action was right or wrong, explicitly citing the relevant rubric or policy clause. This moves the organization away from vibes-based evaluations and toward a rigorous, documented standard.
The ultimate result is defensibility. Over time, this process builds a library of adjudicated truth that you can stand behind. When stakeholders ask months after the fact why an agent approved a specific refund or flagged a piece of content, adjudication provides more than a metric—it provides evidence. You aren't just showing what happened; you are providing the documented reasoning that made the decision correct under the policy in force at the time.
3. The Continuous Calibration Loop
Adjudication shouldn't be a dead end; it should be an engine for improvement. The rationales provided by adjudicators are used to teach the AI judges and refine the prompts. By closing this loop, you reduce the disagreement rate over time, making your automated systems increasingly aligned with expert human judgment.
From Theory to Practice: The ModAI Blueprint
At TrustLab, adjudication isn’t just a theoretical framework, it is a battle-tested methodology refined through high-stakes content moderation deployments.
ModAI is our content moderation platform, designed to orchestrate a hybrid workflow of AI classifiers and human expertise to manage digital safety at scale. Through ModAI, we developed a multi-tiered escalation process to establish defensible ground truth in subjective gray areas. We call this process Root Cause Analysis (RCA), and it serves as an operational blueprint for modern agent adjudication.
The Tiered Hierarchy of Truth
To manage massive decision volumes without sacrificing precision, we utilize a structured hierarchy:
- Tier 1 (Frontline Decisions): AI Classifiers and/or human agents make initial determinations.
- Tier 2 (Quality Assurance): We programmatically sample Tier 1 decisions for a "second look" to catch drift and immediate errors.
- Tier 3 (RCA Adjudicators): When decision makers in previous steps disagree, the case is escalated to our most skilled expert adjudicators. The disagreement can be between different human review tiers or between AI agents and human reviewers.
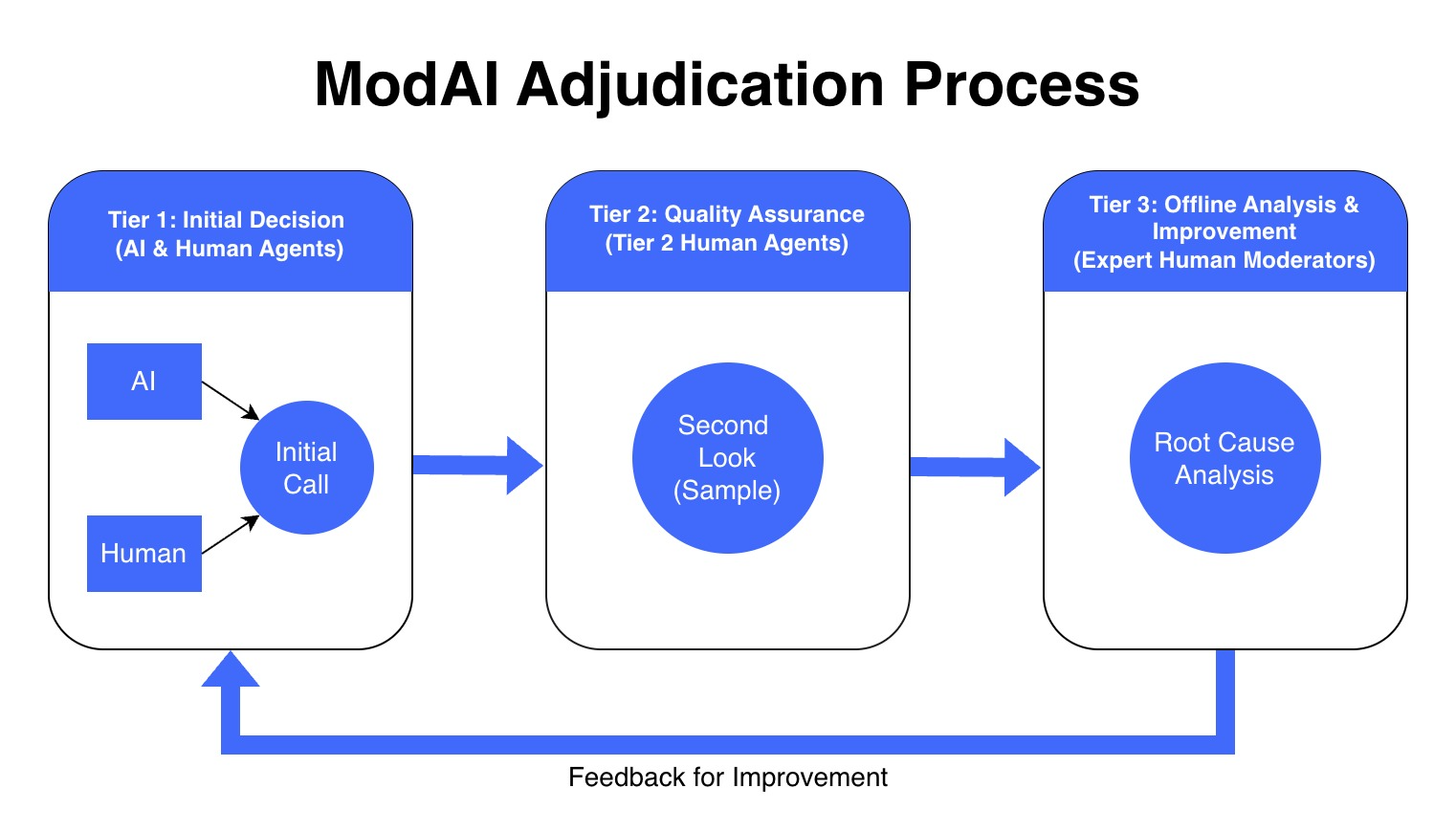
In practice, ModAI’s RCA process operationalizes adjudication: triage what matters, escalate disagreement, and convert subjective edge cases into defensible truth. Crucially, the outcomes don’t stay isolated, they feed back into reviewer training, classifier refinement and customer calibrations, continuously raising the quality of future decisions. With that foundation in place, evaluation stops being a vibe check and becomes an evidence system. ModAI proved adjudication works at scale in moderation.
Beyond Percentages: The Metrics That Matter
If you implement adjudication, your metrics change. You stop looking at success rate in a vacuum and start monitoring the health of your decision-making system, such as:
- Disagreement Rate: How often do your AI judges and human reviewers clash? A spike here often signals a gap in your policy or a shift in user behavior.
- Adjudication Overturn Rate: How often does the final adjudicator change the initial decision? High overturn rates suggest that your initial evaluation layer is biased or poorly calibrated.
- High-Signal Failure Volume: This is the percentage of agent failures that have been successfully converted into adjudicated "golden set" data. Rather than just being errors, these become high-fidelity training examples for error case analysis and agent reinforcement learning pipelines.
Trust as a Competitive Advantage
In the race to deploy AI agents, many organizations will ship quickly. Far fewer will be able to prove with evidence that their agents are reliable, safe, and compliant in production. At TrustLab, we believe that when agents become decision-makers, trust can’t be assumed, it must be built through continuous, adjudicated oversight.
When AI systems were tools, we could afford to trust our instincts. Now they are actors. And actors require accountability. In a world where autonomous agents make real decisions with real consequences, the question is no longer how smart your AI is—it’s whether you can prove it did the right thing, for the right reason, at the right time. Adjudication is that proof. Without it, evaluation is theater. With it, trust becomes infrastructure.


